Using Histograms and Descriptive Statistics to Investigate Process Data
A histogram paired with descriptive statistics helps process improvement practitioners understand distribution, central tendency, spread, and skewness. In this post, learn how to apply these methods to process data, whether for manufacturing parts or service metrics, and make better decisions grounded in data.
A simple summary using descriptive statistics is often the first step in investigating what data can tell you about a process under study during process improvement efforts. Questions like “Where is the central tendency?” or “Is the process skewed?” can be answered quickly by combining a histogram with summary statistics.
For example, imagine a manufacturing line producing a part whose dimension is measured in inches. The same approach applies to transactional processes such as call center wait times or number of users through a system.
Interpreting a Histogram + Key Metrics
A histogram visualizes the distribution of data: how many observations fall within each range. Alongside, descriptive statistics summarize the data using count, mean, standard deviation, and range. A five-number summary tells you where the quartiles lie. Confidence intervals let you estimate true population measures.
When the distribution appears bell-shaped and normal, you gain confidence that the data’s variance is acceptable. If it is skewed or shows multiple peaks, that suggests underlying subpopulations or shifts in process behavior.
Applying These Techniques in Process Improvement
Using histograms and descriptive statistics is not just academic. In Lean Six Sigma and continuous improvement, these tools frequently identify process instability, bias, or drift.
For instance, if a call center measures wait times across shifts, a histogram can show whether one shift consistently has longer delays. Descriptive statistics then quantify how far that shift deviates from the baseline. That insight enables targeted correction rather than generic fixes.
Best Practices and Limitations
Use enough data points to ensure meaningful distributions.
Combine histogram analysis with root cause tools like 5 Whys to dig deeper.
Be cautious: histograms compress data into bins and may hide patterns if bins are too wide.
Use confidence intervals and hypothesis tests to guard against overinterpreting random variation.
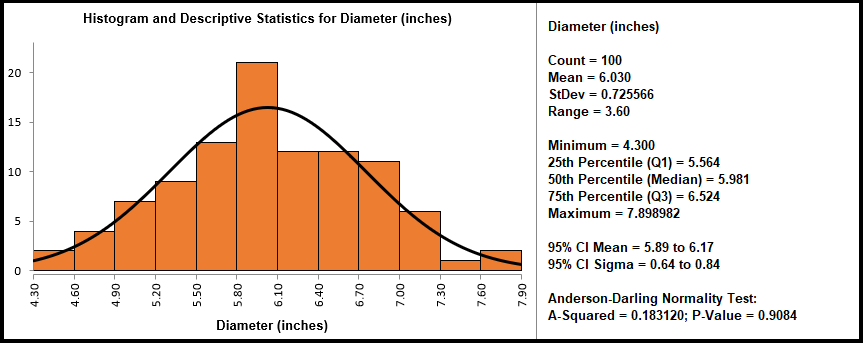
A manufacturing process produces a part that is measured in inches (the same analysis and statistics could also be used in transactional processes such as waiting time in a call center or how many people go through security at an airport). The image above is the histogram for this process along with its descriptive statistics.
The histogram showcases a bell-shaped distribution: the data seem to be normally distributed. This is confirmed by the P-value for the Anderson-Darling normality test, which in this case, is far greater than an assumed alpha risk of 0.05 (or 5%). In this case, our P-value has a strong case in favour of the Null Hypothesis – which states that there is no difference between this dataset and a normally distributed dataset.
Starting at the top of the summary box, a simple run of the key statistics: Count (how many data points), Mean (or average), Stdev (for standard deviation) and Range (another measurement of spread)
The mid-section of the statistics showcases the 5-number summary. Here we can learn about where the data fall in terms of quartiles. Notice that 25% of the data fall under 5.564 inches, the median point is 5.981 inches (50th percentile), and 75% of the data fall under 6.524 inches.
Finally, we can estimate the true population mean and standard deviation by looking at the Confidence Intervals (CI) built for this specific dataset.
In summary, running histograms and descriptive statistics such as these will quickly provide the analyst with important information about the process data under investigation.
I love Continuous Improvement and Data Analytics. The world would be a better place if our kids were taught more process excellence and statistical analysis at school.